AI-tools zijn goedkoop en krachtig. Iedereen gebruikt ze. Maar in de horeca zijn de resultaten vaak teleurstellend. De restaurants die het meeste uit AI halen, hebben geen betere tools. Ze hebben betere data.
Dit artikel legt uit hoe je AI laat werken in een horecabedrijf met meerdere vestigingen.
In de horeca staan te veel feiten op de verkeerde plek
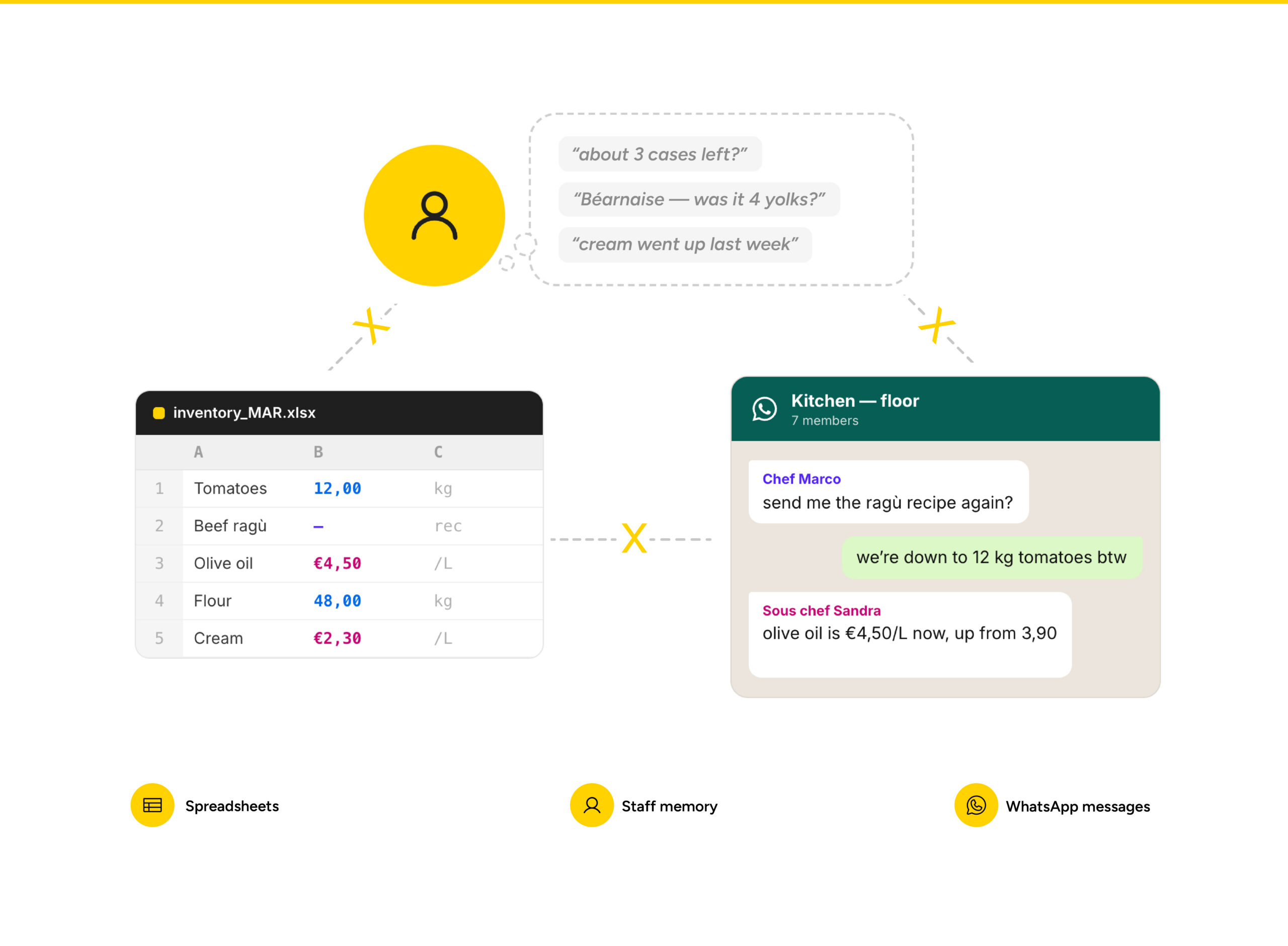
Restaurants hebben data genoeg, maar die is verspreid over spreadsheets, WhatsApp-berichten en het geheugen van het personeel. Als AI op gefragmenteerde informatie draait, moet het gokken – en het klinkt overtuigend, zelfs als het ernaast zit.
Een gebrek aan data is in de horeca nooit echt het probleem geweest. De uitdaging is waar die informatie zich bevindt.
Een verpakkingsgrootte verandert, maar dat is alleen zichtbaar op een factuur. Een chef weet van een vervangend ingrediënt, maar het centrale systeem niet. Een recept heeft lokale varianten per vestiging die alleen in een spreadsheet of in iemands hoofd bestaan.
Dit zijn allemaal operationele feiten. Maar ze worden in het bedrijf doorgegeven via spreadsheets, e-mails, WhatsApp-berichten, handgeschreven notities en het geheugen van het personeel.
Op één locatie is dat meestal nog te overzien. Verspreid over 40, 80 of 300 vestigingen wordt het een groot probleem. Die datasilo’s en omwegen maken niet alleen van je horecabedrijf een black box, ze veroorzaken ook een kettingreactie van onnauwkeurigheden.
Neem de keuken (back of house) als voorbeeld.
Een wijziging in de verpakkingsgrootte beïnvloedt de receptkosten → de receptkosten beïnvloeden de marges op de menukaart → vervangingen van leveranciers beïnvloeden de inkoop → wat weer invloed heeft op de voorraadniveaus, het allergenenbeheer en de productconsistentie.
Het bedrijf heeft de data nog ergens, maar het verliest een betrouwbare versie van de werkelijkheid: wat een product werkelijk is, wat een recept echt bevat, of welke leveranciersprijs klopt.
En daar wordt AI riskant.
AI werkt het best als het toegang heeft tot gekoppelde, betrouwbare operationele data.
Onderzoek van McKinsey maakt dit duidelijk. Als informatie verspreid zit over losgekoppelde systemen en informele processen, moet AI de gaten zelf opvullen. Met andere woorden: het moet aannames doen. Soms kloppen die aannames. Soms niet.
Een AI-assistent zou bijvoorbeeld kunnen melden dat de food cost is gestegen omdat de leveranciersprijzen omhoog gingen. Dat klinkt plausibel. Maar als er belangrijke gegevens ontbreken, kan het de echte oorzaken volledig missen, zoals receptwijzigingen of een inconsistente registratie van verspilling.
De uitdaging is dat AI heel overtuigend klinkt, zelfs als het ernaast zit.
Voor managementteams is dat een reëel risico. AI lost gefragmenteerde F&B-activiteiten niet als bij toverslag op. En omdat mensen de antwoorden vaak vertrouwen, bestaat het risico dat ze die voor waar aannemen, ook als ze niet kunnen zien hoe de AI tot zijn conclusies is gekomen.
Feiten hebben software nodig
AI is geweldig in interpreteren en uitleggen, maar het is het verkeerde gereedschap om basisfeiten zoals receptkosten of allergenen vast te houden. Traditionele software volgt vaste regels en geeft elke keer hetzelfde antwoord. Je hebt beide nodig: software om de gegevens bij te houden, AI om er betekenis aan te geven.
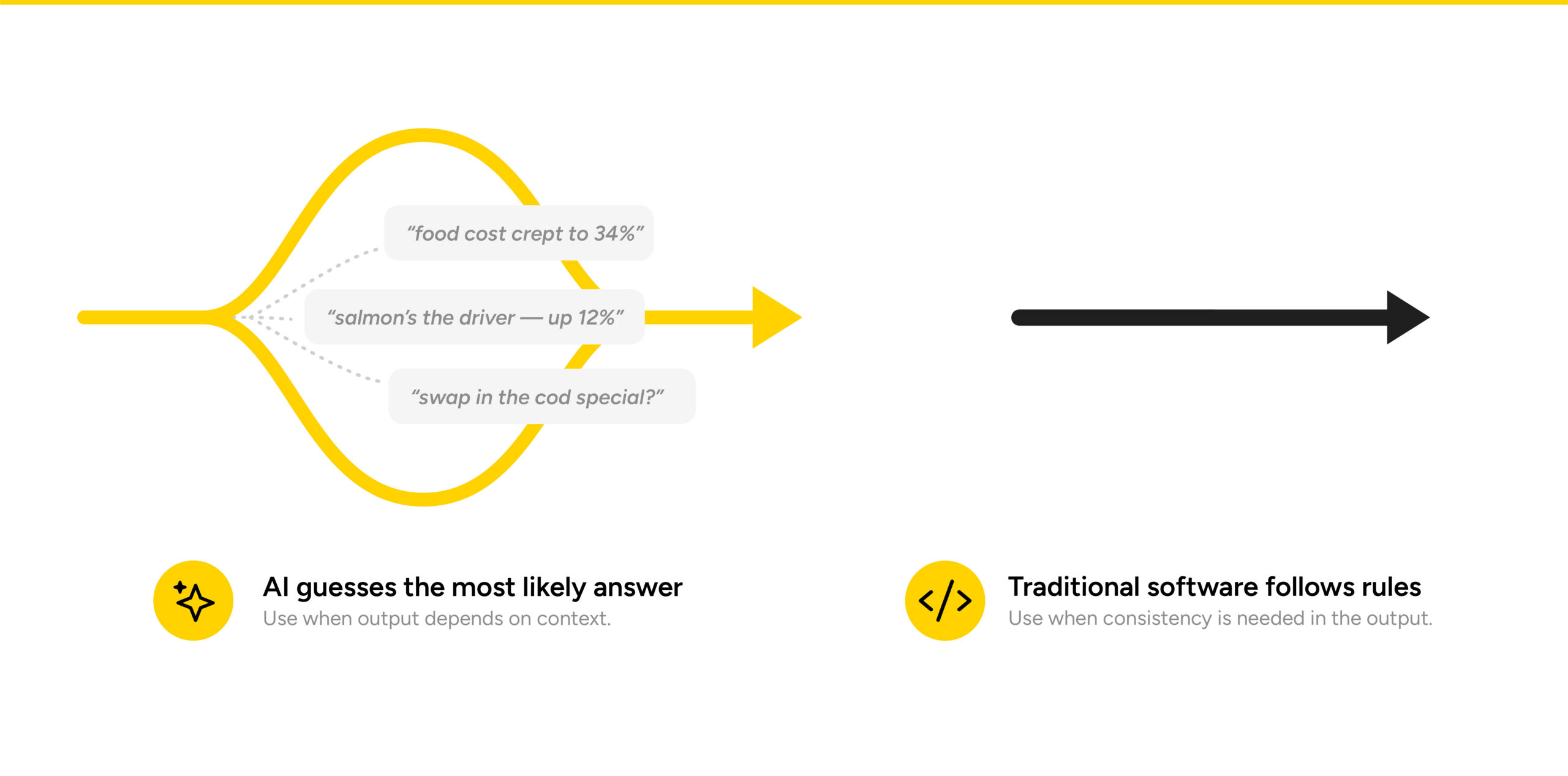
AI is briljant in analyse. Het herkent patronen, verklaart afwijkingen en brengt inzichten naar boven waar mensen veel langer over zouden doen. Maar het kent niet zomaar een product-ID, tenzij het al toegang heeft tot de juiste bron van waarheid.
Elk bedrijf draait op feiten. Die moeten stabiel, consistent en verifieerbaar zijn.
In de horeca hebben producten verpakkingsgroottes, hebben ingrediënten kosten en hebben menu-items allergenengegevens. Die gegevens moeten elke keer kloppen, zonder dubbelzinnigheid of giswerk. Een allergenenmarkering mag niet veranderen omdat iemand een vraag anders heeft geformuleerd.
Maar zo werkt AI niet.
AI is ontworpen om taal, patronen en context te interpreteren. Dat maakt het zo krachtig om te begrijpen en uit te leggen wat er gebeurt. Maar het maakt het ook een riskante autoriteit voor het beheren van centrale operationele gegevens.
Traditionele software daarentegen is daar juist voor gebouwd.
Als aan een softwaresysteem wordt gevraagd wat de kostprijs van een recept is, doet het geen onderbouwde gok. Het volgt een set vooraf bepaalde regels en berekeningen om elke keer een consistent, herhaalbaar antwoord te geven.
Daarom lossen AI en traditionele software verschillende problemen op, en daarom spelen ze verschillende rollen in de tech-stack van restaurants. Software houdt de gegevens bij. AI helpt mensen begrijpen wat die gegevens betekenen.
Dat betekent niet dat AI geen rol speelt in het beheren van data. Integendeel. Het kan facturen lezen, productmatches voorstellen, afwijkingen opsporen en problemen signaleren die aandacht verdienen. Maar die output hoort thuis binnen een op regels gebaseerd systeem dat de data valideert en bestuurt. AI kan helpen om informatie te onderhouden; het zou er niet de uiteindelijke autoriteit over moeten zijn.
De kwaliteit van AI-inzichten hangt altijd af van de kwaliteit van de onderliggende data.
En daar lopen veel operators tegenaan. Volgens een Deloitte-onderzoek onder directieleden in de horeca is 73% van plan om meer in AI te investeren, terwijl minder dan één op de vijf gelooft dat ze de governance-infrastructuur hebben om dat te ondersteunen.
Met andere woorden: veel bedrijven investeren in de motor voordat de weg klaar is. Zonder betrouwbare operationele data kan zelfs de meest geavanceerde AI maar een onvolledig beeld analyseren. Het resultaat zijn niet per se betere beslissingen, maar snellere beslissingen op basis van onzekere informatie.
Wat betekent governed data?
Governed data betekent dat bedrijfstermen en -statistieken gestandaardiseerd zijn, zodat iedereen dezelfde definities gebruikt. De toegang is geregeld, zodat alleen bevoegde gebruikers gevoelige informatie kunnen bekijken of bewerken. De organisatie kan nagaan waar data vandaan komt en hoe die is veranderd. En fouten, duplicaten en inconsistenties worden opgespoord en gecorrigeerd.
Datahubs met uitwisselbare AI
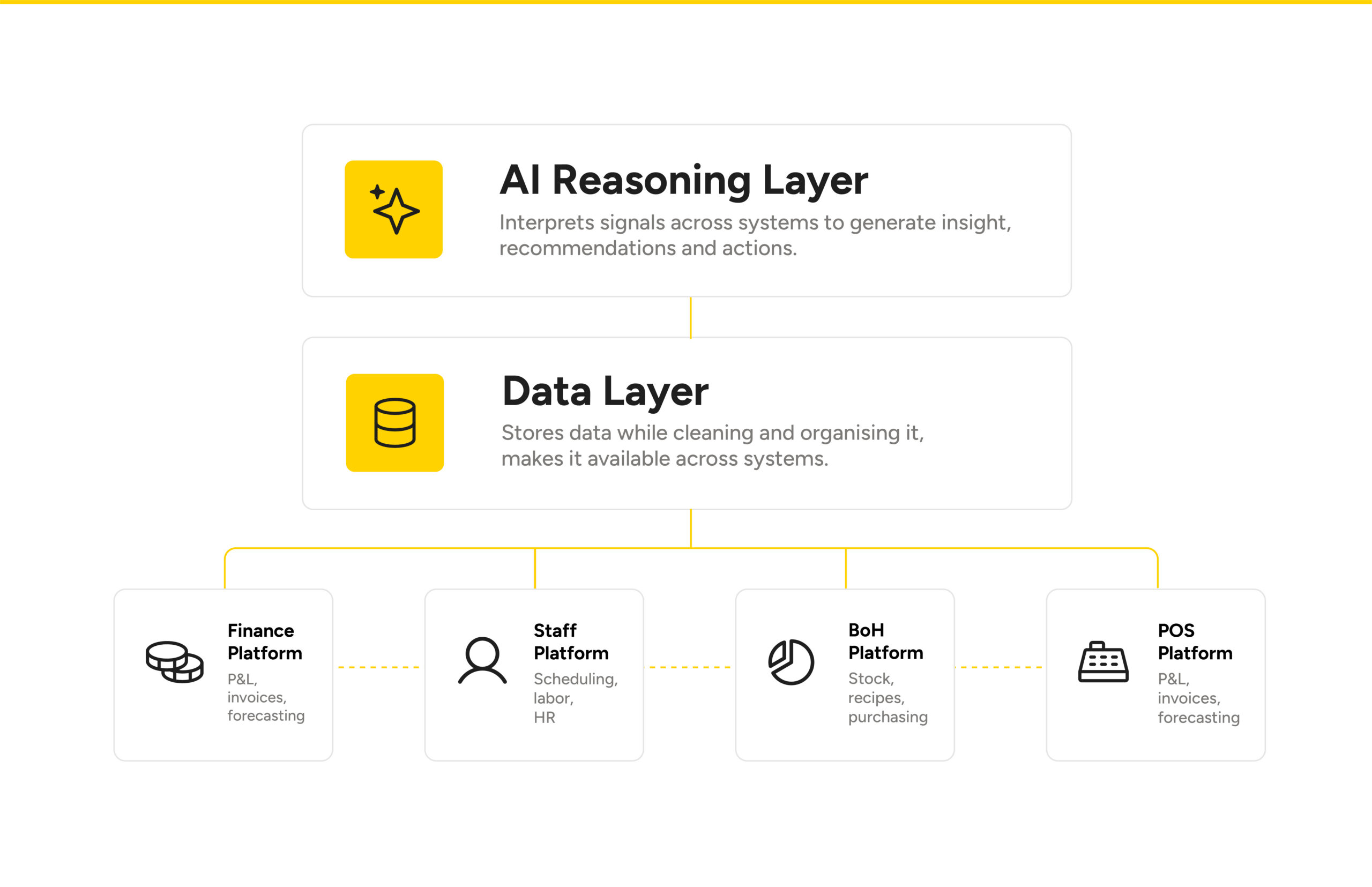
Horeca-activiteiten zijn te complex voor één systeem. Elke bedrijfsafdeling heeft een gespecialiseerd platform nodig dat via API’s koppelt. AI zit boven op die stack. AI-modellen komen en gaan. Data blijft. Als de data-architectuur betrouwbaar is, kun je de AI vervangen zonder het bedrijf te verstoren.
Als operationele informatie verspreid zit over losgekoppelde systemen, spreadsheets en de kennis van het personeel, is de voor de hand liggende vraag: waar zou die informatie eigenlijk moeten leven?
Het antwoord is niet één gigantisch systeem.
Moderne horecabedrijven werken het best met een gekoppelde set gespecialiseerde platforms, die elk verantwoordelijk zijn voor een specifiek bedrijfsdomein en de data beheren die ze het best begrijpen.
Financiële systemen beheren financiële data. Personeelsplanningsplatforms regelen arbeid en roosters. CRM-systemen beheren klantgegevens. En de keuken heeft een eigen operationeel platform nodig, zoals Apicbase, dat begrijpt hoe recepten, voorraad, verspilling, inkoop en marges met elkaar samenhangen.
Als deze systemen gekoppeld zijn, kan AI er als redeneerlaag bovenop zitten.
Deze aanpak staat bekend als best-of-breed-architectuur. In plaats van elke bedrijfsfunctie in één platform te persen, gebruiken restaurantexploitanten gespecialiseerde systemen die informatie delen via API’s. Elk systeem doet waar het het best in is en draagt tegelijk bij aan een breder, gekoppeld technologie-ecosysteem.
Bij grotere horecagroepen met complexere tech-stacks wordt de informatie uit deze operationele systemen vaak samengebracht in een data lake of datawarehouse.
Zo ontstaat een tech-stack met drie lagen:
- Applicatielaag
Hier gebeuren de dagelijkse activiteiten.
Denk aan systemen zoals F&B-managementsoftware (Apicbase), POS-platforms, personeelsplanningstools en financiële systemen. Deze applicaties draaien workflows, handhaven bedrijfsregels en maken en updaten operationele gegevens. - Datalaag
Dit is de centrale opslagplaats voor informatie van de organisatie.
Data uit operationele systemen wordt verzameld, opgeslagen en georganiseerd in een data lake of datawarehouse, wat een consistente basis vormt voor rapportage, analyse en besluitvorming. - AI-laag
Deze laag zit boven op de data.
AI kan context interpreteren, patronen herkennen, voorspellingen genereren, informatie samenvatten, acties aanbevelen en vragen beantwoorden. In plaats van zelf gegevens bij te houden, gebruikt AI betrouwbare operationele data om mensen te helpen begrijpen wat er gebeurt en wat de volgende stap is.
Misschien wel het meest verrassende aan deze architectuur is dat het kiezen van de AI-tool vaak de makkelijkste beslissing is.
Claude, Copilot, ChatGPT, Gemini, Mistral en andere zijn allemaal capabel, betaalbaar en makkelijk in gebruik te nemen. De echte uitdaging is niet het kiezen van een model, maar ervoor zorgen dat de data erachter accuraat, gekoppeld en betrouwbaar is.
De modellen zelf blijven evolueren. Er komen nieuwe aanbieders bij, mogelijkheden verbeteren en kosten veranderen. Bedrijven zouden de flexibiliteit moeten hebben om tussen AI-aanbieders te wisselen naarmate de markt zich ontwikkelt.
Wat niet zou moeten veranderen, is de kwaliteit van de onderliggende data.
Dat fundament moet betrouwbaar, gestructureerd en beheerd blijven, ongeacht welk AI-model het analyseert.
Uiteindelijk hebben restaurants systemen nodig die weerspiegelen hoe ze echt werken.
Als operationele data in de juiste systemen wordt beheerd en door het hele bedrijf wordt gekoppeld, kunnen zowel mensen als AI vanuit dezelfde versie van de werkelijkheid werken. En dat is wat AI van een hypetechnologie verandert in een echt nuttige technologie.
Waarom niet één groot systeem dat alles doet?
Grote ERP’s zoals SAP werken voor de retail. De horeca is anders: ingrediënten worden verwerkt tot recepten, voorbereide items gaan terug de voorraad in en gerechten putten de voorraad op complexe manieren uit. Dat vereist een systeem dat is gebouwd voor de logica van de horeca.

Op het eerste gezicht lijkt het logisch dat grote restaurantgroepen alles centraliseren in één enterprisesysteem zoals SAP of Oracle NetSuite. Eén platform belooft minder datasilo’s, eenvoudiger leveranciersbeheer en één plek om informatie te beheren.
Toch stappen volgens McKinsey veel grote organisaties van die aanpak af.
Hoe komt dat?
Omdat de horeca een mate van operationele complexiteit kent waar generieke ERP-systemen nooit voor zijn ontworpen.
In de retail worden producten doorgaans als hetzelfde item gekocht, opgeslagen en verkocht. Een supermarkt koopt een fles water, slaat die op en verkoopt vervolgens diezelfde fles water. De voorraadstroom is relatief lineair, en ERP-systemen zijn er extreem goed in om dat op schaal te beheren.
Maar de horeca werkt heel anders.
Ingrediënten worden voortdurend verwerkt voordat ze de klant bereiken.
Een doos tomaten wordt misschien in de voorraad opgenomen, verwerkt tot tomatensaus, als halffabricaat teruggezet in de voorraad, gebruikt in meerdere recepten en vervolgens weer uitgeput naarmate gerechten worden verkocht.
Hetzelfde ingrediënt kan meerdere productiestadia doorlopen voordat het ooit op het bord van een gast belandt.
Het beheren van dat proces vereist een fundamenteel ander operationeel model binnen het systeem.
Het systeem moet recepthiërarchieën, productieworkflows, opbrengstberekeningen, verspilling, vervangingen, voorbereidingsprocessen, voorraadbewegingen en inkooprelaties begrijpen. Dat is veel meer dan alleen financiële transacties en voorraadoverboekingen.
Daarom is software met specifieke domeinexpertise zo belangrijk.
Wat eerst een operationeel vraagstuk was, werd ook een AI-vraagstuk.
Zoals Gartner heeft opgemerkt, blijven slechte datakwaliteit en zwakke datafundamenten tot de belangrijkste redenen behoren waarom AI-initiatieven geen waarde opleveren. Als een bedrijf de systemen mist om de realiteit van de keuken vast te leggen en te besturen, maakt AI weinig kans om betrouwbare inzichten te leveren.
Kan MCP dit niet oplossen?
Nee. MCP (Model Context Protocol) geeft AI-tools zoals ChatGPT en Copilot een veilige manier om externe data te benaderen. Apicbase biedt een MCP, zodat gebruikers verkoop-, voorraad- en inkoopdata rechtstreeks vanuit die tools kunnen opvragen.
De MCP is de verbinding, niet de intelligentie. Zie de MCP als een sleutel. Het opent de deur naar de data, maar het bepaalt niet welke data juist is. Dat doet Apicbase.
Hoe werkt dit in de keuken?
Apicbase is het besturingssysteem voor de keuken (back of house) dat restaurants met meerdere vestigingen de schone datafundering geeft die AI nodig heeft.

Operators gebruiken Apicbase om recepten, voorraad, inkoop en food cost op één plek te beheren.
Apicbase lost het F&B-datafunderingsprobleem op vier manieren op.
- Single source of truth
Ingrediënten, leveranciersartikelen, recepten, prep-items, allergenen, voorraadbewegingen en vestigingen bevinden zich allemaal in één gedeeld datamodel.
Leveranciersartikelen koppelen rechtstreeks aan ingrediënten. Prep-batches kunnen terug de voorraad in. De voorraad wordt automatisch afgeboekt zodra menu-items worden verkocht.
Apicbase begrijpt hoe deze entiteiten met elkaar samenhangen, wat een governed operationeel register over alle vestigingen heen oplevert. - Gekoppelde operationele cyclus
De activiteiten in de keuken zijn geen losse workflows. Inkoop beïnvloedt de voorraad. Voorraad beïnvloedt de receptkosten. Receptkosten beïnvloeden de marge. In Apicbase is die cyclus in het systeem ingebouwd.
Het personeel hoeft geen spreadsheets met elkaar te verzoenen om te begrijpen wat er speelt.
Als een leveranciersprijs verandert, werkt het effect automatisch door in receptkosten, marges op de menukaart, inkoopbeslissingen en operationele rapportage. - Geïntegreerde tech-stack
Apicbase is geen geïsoleerd platform. Het koppelt rechtstreeks aan het bredere technologie-ecosysteem van de horeca. Het kan POS-verkoopdata inlezen, zodat voorraad, marge-analyse en prognoses in realtime weerspiegelen wat er daadwerkelijk verkocht wordt over alle locaties.
Het deelt ook gestructureerde F&B-data met financiële platforms, ERP-systemen en BI-tools, zodat elk downstream-systeem met dezelfde data werkt. - De basis voor betrouwbare AI
De data die Apicbase genereert is gestructureerd, gekoppeld en consistent. Daardoor kan AI margebewegingen verklaren, inkoopbeslissingen voorstellen, de vraag voorspellen en afwijkingen signaleren – met grote nauwkeurigheid.
Apicbase heeft ingebouwde AI en een MCP die data veilig ontsluit voor Claude, ChatGPT, Copilot en andere AI-tools.

Data is je voorsprong
AI-tools zijn goedkoop, krachtig en makkelijk te gebruiken. Ze produceren in minuten wat vroeger teams analisten weken kostte. Maar er is een addertje onder het gras: de output is maar zo goed als de data erachter. Dat betekent dat de echte voorsprong uit de datalaag komt, niet uit de AI zelf.
Apicbase geeft F&B-operators dat fundament en ordent recept-, voorraad- en compliancedata over elke locatie.
Met betrouwbare data op orde kunnen bedrijven meer vertrouwen hebben in hun rapportage, hun activiteiten en de AI-gestuurde inzichten die daarop zijn gebouwd.
Wil je zien hoe dat eruitziet voor jouw bedrijf?